研究背景
近年来,具有数十亿参数的人工智能(AI)技术给各领域带来了变革性的变化,为高效解决这些 AI 任务,对高性能和 AI 芯片的需求激增。最近,先进芯片领域取得了较大进展,例如光子计算的发展、量子处理器的进步、仿生芯片的性能提升等等。先进芯片的设计需要对材料、算法、模型、架构等方面进行精心考虑。尽管有一些综述从其独特的角度介绍了芯片的发展,但从先进设计的角度围绕高性能和 AI 芯片展开的综述却很少。在此,对先进芯片领域的最新发展进行了系统性综述。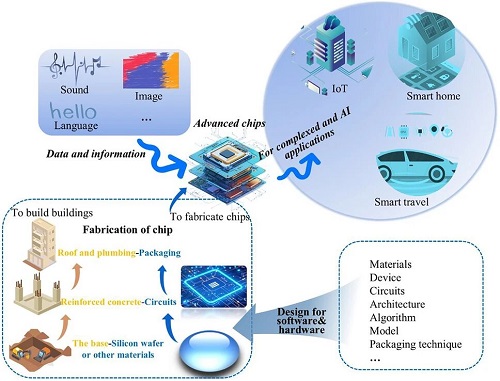
Advanced Design for High-Performance and AI Chips
Ying Cao, Yuejiao Chen, Xi Fan, Hong Fu* & Bingang Xu*
Nano-Micro Letters (2026)18: 13
https://doi.org/10.1007/s40820-025-01850-w
本文亮点
1. 本文对高性能和AI芯片的最新进展进行了全面综述。
2. 高性能和AI芯片的设计可以从多个方面进行,包括材料、电路、架构和封装技术,以追求多模态数据处理能力、强大的可重构性、高能效和出色的计算能力。
3. 提出了对高性能芯片未来发展方向的展望。
内容简介
过去十年间,AI技术取得了飞速的发展,并带来了众多领域的变革,包括信息的解读方式、新材料的发现方法、创新工作的开展方式等等。AI模型包含数十亿个参数,用于实现高精度计算,这对处理器的能源效率等方面提出了很高的要求。香港理工大学徐宾刚教授聚焦高性能及AI芯片的先进设计方式,围绕对现有硅材料和硅技术进行改进,以及开发新型材料和模式,例如光子计算和量子处理器等,综述了近年来的最新研究进展。首先介绍了AI芯片的研究背景及其工作原理,随后分别从传统硅基芯片的研究进展以及采用将信息处理方式从电子扩展到光子、量子和生物元素的新模式两个方面,展示了有关软件和硬件的协同设计理念。从信息处理流程的角度讨论了在设计高性能芯片时应考虑的关键因素。最后,提出了关于先进芯片发展前景的一些展望。文章通讯作者为徐宾刚教授,第一作者为曹莹博士。
图文导读
I 机理
如图1所示,芯片用于处理各种信息和数据。其中,数据可以从多模态传感器中收集。对于一个典型任务,信息首先由传感器捕获,然后通过大量模数转换器(ADC)进行数字化(图1a),随后数据会被处理并进行传输(图1b 和c)。从环境中收集到的复杂多模态信息会被具备高处理能力的芯片来计算、处理(图1d),进而完成各类复杂任务(图1e)。为了提升系统的整体性能,相关研究人员进行了大量的努力,采取了一系列措施,包括借鉴高级的大脑动态机制(图 1f)、采用仿生设计方法(图 1g)、以及应用新型模式(图 1h)等。例如,光子处理器被认为将成为基于硬件的AI加速器的关键技术之一,每个输入相干光在不同波长所携带的数据可以由相变材料光子存储器加权。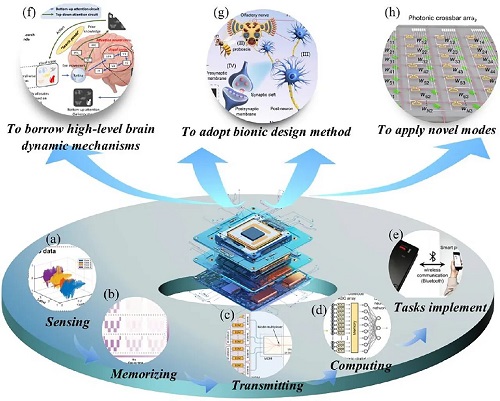
图1. 先进芯片工作机理及性能提升方法示意图。(a) 感应、(b) 记忆、(c)信息传递、(d)计算、以及(e)任务完成阶段的示意图;通过(f)借鉴高级的大脑动态机制、(g)采用仿生设计方法、以及(h)应用新型模式等方式提升系统的整体性能。
II 软件、硬件协同设计
AI依靠硬件和软件来学习和模拟人类智能,对于先进的AI芯片而言,进行软件和硬件的协同设计至关重要。具体而言,软件设计对于神经网络的构建和训练至关重要,而硬件则对于处理数据以完成AI领域的各类复杂任务极为关键。 人类大脑所具备的复杂认知能力引发了对AI的广泛研究,并推动了基于复杂大脑模型的算法的发展。值得一提的是,为了实现实际应用,需要对设备与算法进行协同优化。特别是对包含数据管理、模型模拟和主机管理的软件工具链的开发有助于高效地部署算法和模型,以应用于各种场景。
2.1 软件设计
2.1.1 与硬件协同设计
软件的设计需与硬件协同进行。例如,相关研究努力将大脑的高级动态计算特性与机器智能相结合,使神经形态计算具有能量优势。神经科学中基于注意力的动态响应的示意图如图2a所示。具体而言,硬件的开发是为了满足动态计算的需求,这表明无输入不消耗能量;与此同时,基于注意力的框架设计,可以应对动态计算的挑战,其特点是不同的输入消耗的能量差异很大。从神经科学中的视觉注意机制得到启发,设计了动态脉冲神经网络(SNNs),典型的尖峰神经元模型和基于注意力的动态SNN如图2b,2c所示。
2.1.2 开展算法设计
AI的迅猛发展所带来的一些挑战可以通过算法的设计来应对。比如随着AI生成内容的快速发展,需要处理多种类型的数据。例如,相关研究指出,大多数用于深度学习(DL)的光子神经形态处理器只能处理单一数据模式,原因是光学领域缺乏大量用于训练的参数。为了解决这个问题,开发了一种可训练的衍射光学神经网络(TDONN)芯片,其中,为多模态分类任务设计的光学神经网络模型由三部分组成,包括一个输入层、五个隐藏层和一个输出层(图2d)。此外,设计了梯度下降算法以及光神经元的暂退法,以实现该功能。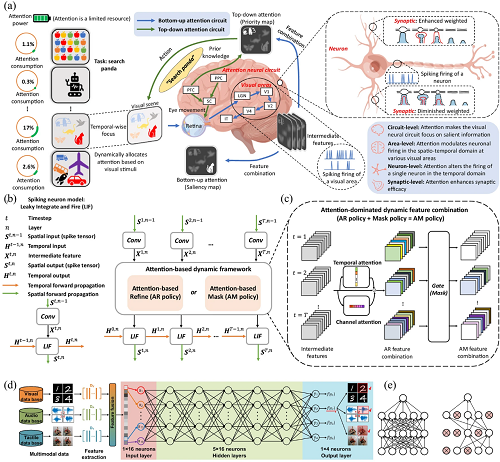
图2. 软件设计如何推动先进芯片开发的示意图。(a) 神经科学中基于注意力的动态响应的示意图。(b) 一个典型的脉冲神经元模型和 (c) 基于注意力的动态SNN的示意图。(d)用于多模态分类的光学神经网络模型的示意图。(e) drop-out算法的示意图。
2.2 硬件设计
硬件设计对于促进不同类型芯片的发展都是必不可少的。具体来说,忆阻器能够模拟生物突触的可塑性,因此在脑启发式计算中发挥着关键作用。光子计算具有超高速的特点,但同时也存在与硅基电子芯片兼容性差的问题。量子计算在处理特定问题方面的计算能力远远超过传统计算机,但极低温度的要求通常是一个挑战。神经形态计算旨在模仿人类大脑的结构,并通过异步 SNN 实现事件驱动计算,适用于实时感知和物联网应用等领域。因此,在硬件方面,需要进行新的电路布局或材料结构设计以满足这些不同类型芯片的需求与挑战。
2.2.1 开发新材料
材料的发展是芯片产业蓬勃发展的最重要支撑之一。例如,基于存内计算(CIM)的硬件系统是根据AI算法的要求设计的,旨在通过消除内存与处理单元之间的频繁数据传输来加速大量计算。相应地,研究者在非易失性存储器的开发方面进行了许多努力。此外,关于硬件设计,还希望通过采用高效算法,实现更高级的功能,同时保持较低的硬件成本和较高的灵活性,以满足不同应用场景的需求,这对材料的开发也提出了很多新要求。关于硬件的设计,需要考虑一系列因素,比如稳定性、一致性以及大规模实现的可行性等。
2.2.2 开发新模式:神经形态计算
研究人员作出了大量尝试将神经系统中的生物行为与各种设备中的电行为进行对应映射,并且出现了许多新技术推动神经形态计算的进一步发展,以应对AI任务所带来挑战。例如,大量数据在内存与处理器之间传输时会出现过度的能量消耗,这被称为“冯·诺依曼瓶颈”。 CIM被提出作为一种有望应对因迅猛增长的计算任务而带来的挑战的可行方法,在近年来得到广泛关注。尽管在电路集成技术方面已经取得了显著进展,但对于线性矩阵向量乘法运算后的结果的大部分非线性计算,都依赖于传统的互补金属氧化物半导体(CMOS)电路,其中包括用于复杂运算的数字电路,查找表(LUT)作为激活单元会导致过大的面积和能耗成本(图3a)。金字塔神经元的钙介导树突动作电位(dCaAPs)和胞体动作电位,展示了不同的逻辑功能,并能够实现异或分类(图3b),这给神经形态计算提供了新的启发。二氧化钒(VO₂)是一种被充分研究的莫特材料,其在电或热刺激下表现出独特的绝缘体到金属的转变(IMT),这促使研究人员研究其非线性电阻(NDR)特性作为神经网络中传统激活单元的潜在替代者。VO₂的NDR特性与IMT如图所示3c,测试结果表明在单个器件中可以实现异或运算。如图3d所示,通过将 1T1R 电阻式随机存取存储器RRAM 数组与 VO₂ NDR 神经元集成可以完成深度神经网络的全硬件实现。
2.2.3 开发新模式:光子计算
在后摩尔时代,对于更高性能芯片的持续需求给相关领域的研究带来了更大的挑战。光子计算凭借前所未有的高速度和低能耗的计算方式展现出了显著的优势,这使得数据处理速度更快、更节能。在光子计算中,光的特性被用于承载信息,其传播和干涉被利用来进行计算。与此同时,AI在光学领域的应用可以促进光学系统的设计和控制。
2.2.4 开发新模式:量子计算
除神经形态计算和光子计算外,量子计算也已作为另一种先进的计算类型出现。为了推动自旋量子比特技术的应用,物理量子比特数量需要大幅增加,这就使得制造出密度、体积和均匀性与由数十亿个晶体管组成的经典计算芯片相当的自旋量子比特器件变得至关重要。自旋量子比特技术因其量子比特尺寸带来的固有可扩展性优势而独具特色,并且具备与 CMOS 工艺技术的天然兼容性。基于硅中电子的自旋量子比特已展现出良好的控制保真度,但关于产量和工艺等各个方面的挑战依然存在。最近,在解决这些问题上已取得了一些进展。例如,相关研究开发了一种测试流程,使用低温 300 毫米晶圆探测器来收集数百个自旋量子比特器件在 1.6 开尔文下的大量性能数据。这种测试方法能够提供快速反馈,从而优化与CMOS兼容的制造工艺。图3e展示了Si/SiGe量子点量子比特装置的横截面透射电子显微镜图像。如图3f所示,当晶圆处于低温状态时,通过晶圆平台控制和机器视觉反馈将器件引脚与探针对齐。平台将器件引脚抬升至与探针接触的位置,以便在室温下将器件连接到测量电子设备上。在设备接触状态下,可以进行各种测量以提取器件数据(图3g)。在晶圆上对许多器件重复此过程后,可以使用设备数据进行统计分析(图3h)。
2.2.5 提升封装技术
除开发适用于先进芯片的新材料和新模式外,在集成技术方面也取得了很大进展。单片三维(M3D)集成技术已被提出,即通过在同一片晶圆上依次沉积上层结构来制造多个堆叠层级,以克服尺寸缩小的限制并实现更高的器件密度。它还能够构建新的三维计算系统,在这种系统中,诸如逻辑、存储器和传感器等不同层级能够实现垂直互连。例如,相关研究报到了一种低温M3D集成方法,即对整个预制电路层进行范德瓦尔斯(vdW)层压。M3D集成过程包括在牺牲基底上进行电路层的预制(图3i),物理剥离电路层(图3j),然后使用vdW转移技术将其叠到目标二维表面上(图3k)。 光学图像和在 2 英寸牺牲基底上预制的电路层级的放大图像如图3l和m所示,最终器件的光学图像如图3n所示。 图3o和p分别展示了10 层 M3D 系统的示意图和光学图像。该研究成果为制造层数更多的M3D电路提供了一条低温工艺路径。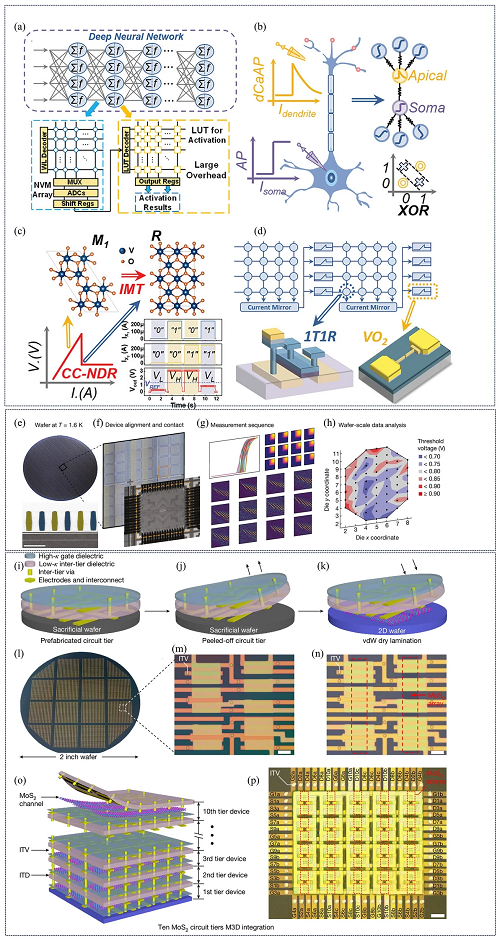
图3. 硬件设计如何促进不同类型芯片的发展。(a) 神经网络结构的示意图以及如何通过传统硬件实现;(b) 钙介导的树突动作电位(dCaAPs)与传统全或无动作电位的示意图;(c) NDR、IMT以及在单个器件中实现的异或运算的示意图;(d) 神经网络完全通过硬件实现的示意图;(e) 冷冻探针能在约 2 小时内将 300 毫米厚的晶圆冷却至 1.6 开尔文的电子温度;(f) 设备对齐和接触的示意图;(g) 用于提取数据的各种测量方法;(h) 如何使用设备数据进行统计分析;(i) 在牺牲基底上进行电路层的预制; (j) 物理剥离电路层,以及 (k) 使用vdW转移技术将其叠到目标二维表面上; (l) 光学图像和 (m) 在 2 英寸牺牲基底上预制的电路层级的放大图像; (n) 最终器件的光学图像; (o) 10 层 M3D 系统的示意图和 (p) 光学图像。
III 未来先进及AI芯片的设计考量因素
随着AI技术的发展,计算量急剧增加。AI的迅猛发展在很大程度上得益于对大量数据计算能力的提升。例如,对于许多视觉任务而言,实现超低延迟完成任务至关重要,这需要极高的计算能力。此外,能源效率也是高性能计算中需要平衡的关键问题。
3.1 用于高性能计算
计算速度应进一步加快,以配合算法层面各种任务性能的提升。通过充分利用光学和光子学,光学AI能够实现大带宽和高能效计算。一个不容忽视的事实是,光学信号需转换为数字信号,才能进行必要的后续处理(图4a),而用于数字处理的ADC能耗较大,且对噪声和系统错误较为敏感性。为解决这一问题,研究者提出了一种结合电子和光计算的全模拟芯片(ACCEL),其工作流程如图4b所示,全模拟光电子芯片的示意图见图4c。该系统实现了实现了4.6 Peta-OPS的系统级计算速度,系统级能效达到74.8 Peta-OPS/W。
光学计算所面临的另一个挑战在于,它们是在电子计算机中以模拟形式实现的,因此严格的建模以及大量的训练数据都是必不可少的(图4d)。一般光学系统包含调制区(深绿色)和传播区(浅绿色),其中折射率分别可调和固定(图4e)。为解决这一问题,研究者提出了一个全前向模式(FFM)学习方法,可在物理系统上实现训练过程(图4f)。
除了上述方法之外,并行多线程处理也是实现高速和大容量信号处理的关键方法之一,近年来涌现出很多相关研究成果。现有的光子张量核使用相干光源进行计算,需要实现对光源波长和相位的精准控制(图4g)。研究人员引入了一种光子卷积处理系统(图4h),该系统利用部分相干光来提高计算并行性(图4i),同时又不会大幅降低精度,这有可能使更大的光子张量核得以实现。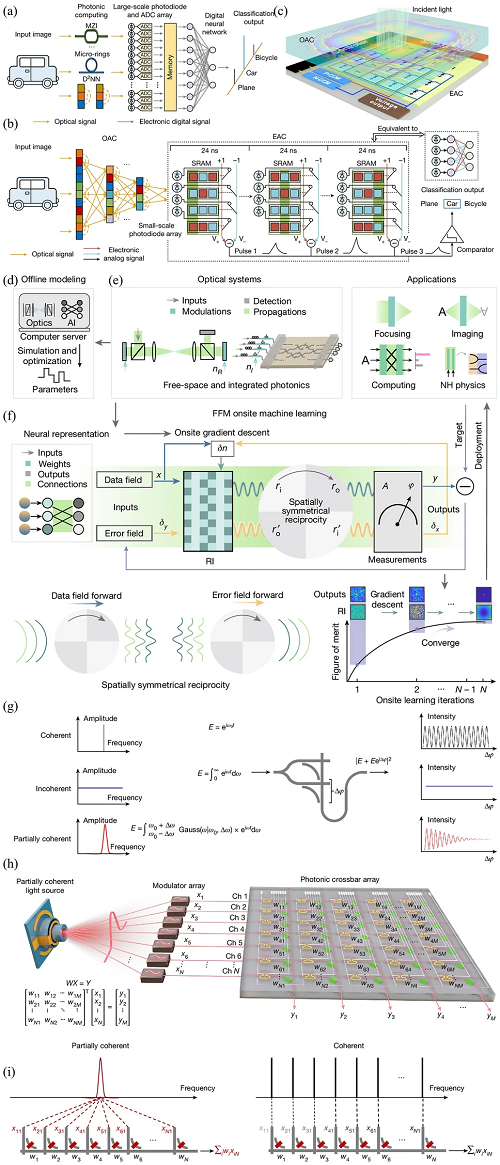
图4. 高性能计算中 AI 芯片的设计考量。(a) 传统光电计算的工作流程;(b) 全模拟光电子计算的工作流程;(c) 全模拟光电子芯片的示意图;(d) 常规光学AI 相关的示意图;(e) 通用光学系统;(f) 光学系统到神经网络映射的示意图;(g) 具有相干光源的通用单元示意图;(h) 部分相干光光子卷积处理系统示意图;(i) 并行性 N 倍增强的示意图。
3.2 提高能量效率
除了提升计算性能之外,先进芯片还需要具备高能效这一重要特性。例如,在许多视觉任务中,具有高吞吐量和高精度的ADC会由于数据带宽有限而降低成像帧率,从而导致显著的能耗增加。因此,研究者致力于采用全模拟方式设计一种光电混合架构,以减少用于高效节能视觉任务的 ADC 设备。此外,神经形态计算作为一种新方法,对于实现节能型机器智能具有很大的潜力,它通过模拟人类大脑中的神经元,并利用脉冲神经网络来实现。
CIM在AI领域同样非常重要,它可以将存储和处理功能集成到同一个模块中,从而增强了系统的能效。研究人员开发了一种模拟AI芯片,在34个tile中含有3500万个相变存储器,用于语音识别。各芯片的实测功耗及TOPS/W 值如图 5a所示,其中,Chip 4 能效达到 12.40 TOPS/W,且片上权重数量较多。通过缩短最大输入持续时间所实现的TOPS/W 值的提升如图5b所示,从图中也可看出在语音识别等任务中,能效与识别精度之间的关系。不同层级的能效见图5c,其中,模拟 tile 能效最高,全系统能效相对降低。处理时间和实际语音时间如图5d所示,芯片处理时间远小于实际语音时间,说明芯片能满足实时处理需求。在 RNNT 实验中,片上与片外执行的操作数量如图5e所示,每秒每瓦特样本数与TOPS/W 值与 MLPerf 提交结果的对比如图5f所示,从中可以看出,芯片在样本数和能效方面都有显著优势。
人脑能够运行非常复杂的神经网络,总功耗却远小于现有的AI系统。因此,通过借鉴人脑的低功耗特性发展新型智能计算系统成为研究热点之一。例如,研究人员开发了一套能够实现动态计算的算法-软件-硬件协同设计的类脑神经形态系统(Speck),其处理器静态功耗仅0.42mW,能够满足无输入时零能耗的硬件需求。如图5g所示,芯片总功耗由硬件设计和算法设计共同决定。图5h和i对比了不同功耗与算法结合的情况,对于高静态功耗结合先进算法,算法虽能节能,但高静态功耗限制总节能效果,而低静态功耗和先进算法的结合,可更充分发挥算法节能优势,显著降低总功耗。Speck的实物如图5j所示,它集成了动态视觉传感器(DVS)相机和异步神经形态芯片,是传感-计算端到端的片上系统(SoC),具备低延迟、低功耗等特性(图5k),适用于一系列应用场景,如物联网、智能出行、智能机器人、智能家居等(图5l)。Speck 的全异步架构及核心设计如图5m和n所示。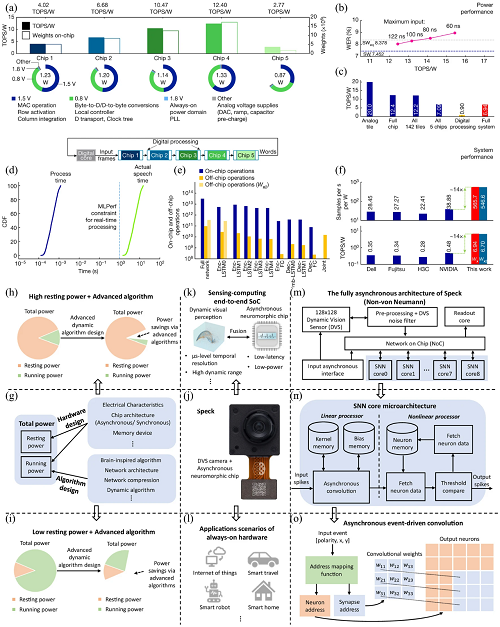
图5. (a) 各芯片的实测功耗及TOPS/W 值;(b) 通过缩短最大输入持续时间所实现的TOPS/W 值的提升;(c) 不同层级的能效;(d) 处理时间和实际语音时间;(e) 在 RNNT 实验中,片上与片外执行的操作数量;(f) 每秒每瓦特样本数与TOPS/W 值与 MLPerf 提交结果的对比。(g) AI 系统的功耗构成;(h)高静态功耗的情况;(i)低静态功耗的情况;(j) Speck 的实物展示;(k)感知计算端到端 SoC 的示意图,以及 (l)其应用场景;(m)Speck 的全异步架构;(n)SNN 核心的设计,以及 (o)异步事件驱动卷积。
IV 总结与展望
由于AI带来的巨大挑战,先进芯片领域取得了巨大进展,这些挑战涵盖了从信息产业到材料科学等各个领域,引发了革命性的变化。为了执行这些新挑战所提出的复杂算法和高级任务,芯片的设计涵盖了材料、算法、架构、处理技术、集成方法等各个方面。在开发新型材料和模型方面取得了进展,同时也克服了现有传统芯片材料和架构的不足。针对器件生产和封装的新型制造工艺已经开发出来,旨在降低成本并制造复杂的芯片。先进的芯片能够应用于视频识别任务、语音识别和转录、视觉记忆以及许多其他领域,提供高效的信息处理功能。对芯片未来的研究和应用前景提出如下展望:
1. 研究者一直致力于使AI芯片生物学中学习到更智能的性能。a) 研究人员将生物行为映射到设备的电学行为上,期望系统能够实现更复杂的生物性能。b) 人们广泛研究了基于人脑的神经形态器件,如何从高级大脑动态机制中学习,以使神经形态计算具备更多能源优势一直备受关注。此外,用于处理图像信息的芯片有望能够应对实际应用中动态、多样且难以预测的场景,比如自动驾驶。研究者期望设计出在各个领域都高效的芯片,以感知并解决现实世界中存在的难题。特别是,该系统已模拟了人脑的关键特性——动态计算。未来,可以采用更先进的策略来实现高级大脑动态机制,从而在诸多方面充分发挥大脑的优势。
2. 充分利用从电子、光子、量子到生物元素的信息处理新方式,发挥其优势,克服其劣势,从而实现信息处理能力的全面拓展。a) 基于光子学的系统设法提供高速计算单元,因此今后的研究可集中在算法设计上,以利用其独特的优势。b)低功耗和实时性的要求推动了CIM 在许多领域的应用。在未来,我们可以通过使用新材料来提高CIM的计算能力。c) 此外,细胞芯片技术已经兴起,其重点在于对真实细胞过程的分析和建模,以实现具有信息处理和适应性的计算功能。
3. 对适用于实际应用的先进芯片需求量很大。在实际应用中,为了处理各种外部信息,通常需要使用适合多种先进处理器来正确处理多输入信号,来自不同输入端的集成信号需要被准确且及时地处理。
4. 可重构行为是计算硬件的一个重要目标。对于具有可重构特性的芯片而言,它们的功能可以改变,因此可以处理多模态数据和完成不同的任务,使芯片适应不同任务,具备高度灵活性成为可能。
5. 对于芯片的大规模集成,预计还将会有更大的需求。随着信息量的不断增加,芯片需要达到越来越高的集成度,以处理日益增多的信号。
6. 在AI芯片中应用可持续材料是该领域最重要的趋势之一,其目的是减少对环境的影响并提高能源效率。为此,可以从多个方面做出努力,例如选择可降解的基板、开发环保的制造工艺、准备环保的散热材料等。
作者简介

关于我们

Nano-Micro Letters《纳微快报(英文)》是上海交通大学主办、在Springer Nature开放获取(open-access)出版的学术期刊,主要报道纳米/微米尺度相关的高水平文章(research article, review, communication, perspective, highlight, etc),包括微纳米材料与结构的合成表征与性能及其在能源、催化、环境、传感、电磁波吸收与屏蔽、生物医学等领域的应用研究。已被SCI、EI、PubMed、SCOPUS等数据库收录,2024 JCR IF=36.3,学科排名Q1区前2%,中国科学院期刊分区1区TOP期刊。多次荣获“中国最具国际影响力学术期刊”、“中国高校杰出科技期刊”、“上海市精品科技期刊”等荣誉,2021年荣获“中国出版政府奖期刊奖提名奖”。欢迎关注和投稿。
Web: https://springer.com/40820
E-mail: editor@nmlett.org
Tel: 021-34207624
如果文章对您有帮助,可以与别人分享!:Nano-Micro Letters » 香港理工大学徐宾刚等综述:高性能与AI芯片的先进设计